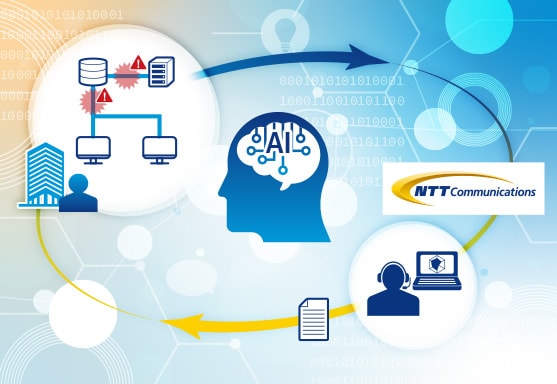
サービス
主なマネージドサービス
大企業・中堅企業向き
-

トータルマネージサービス。
NTTドコモビジネスのベストプラクティスをセミオーダー型で提供詳しくはこちら
-
AWS
導入支援・運用サービス導入アセスメントからマイグレーション、保守運用まで1社完結
詳しくはこちら
-
多店舗ネットワーク
マネジメント24時間365日、多店舗・多拠点ネットワークの一元監視、運用、故障対応
詳しくはこちら
-
Azure
マネージドサービスOpenAI PoCアプリ、短納期モデル提供
詳しくはこちら
-
X Managed®
works with SentinelOne自立型AI搭載の次世代エンドポイントセキュリティ(EPP+EDR)
詳しくはこちら
-
マルチクラウド
マネジメント600以上のシステム・アプリケーション・サービスを一元的に監視
詳しくはこちら
マネージド・関連
全19サービス
- 豊富な拡張
コンポーネント : - セキュリティ 、 監視 、AI検知 、自動化コンポーネント
- 多彩な支援
サービス : - ヘルプデスク 、コンタクトセンター 、デリバリー 、サービスマネージャー

マネージド導入事例
-

多店舗ネットワークの運用監視・
保守業務アウトソーシング事例- 多店舗ネットワーク
- ネットワーク一元監視運用
- マルチキャリア対応
ネットワーク全体の機器最適化/運用コスト削減。各拠点の構成可視化。故障対応の迅速化、震災対応の自動化
-

【事例】Zabbixによる監視システム一元化・運用効率化『ZABICOM』
- ZABICOM(Zabbix)
- システム監視運用
- オールインワン
監視システムの自動化による人為ミス削減、業務負荷軽減。複雑な監視運用の差異、優先順位のヒアリングをもとにした構成整理による監視漏れの防止、監視対応品質の統一。大規模監視に対応した短期チューニングによるスピーディーな導入を実現。
-

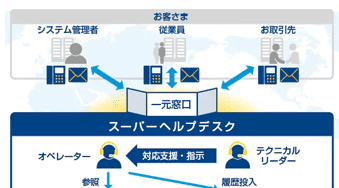
グローバルヘルプデスクの一元体制でガバナンス強化 - スーパーヘルプデスク導入事例
- スーパーヘルプデスク
- グローバルヘルプデスク
- グローバルガバナンス強化
グローバルで統一された高品質な従業員サポートによる従業員満足度(ES/EX)の向上。各リージョンの運用状況を把握、課題を分析し改善することよるサービス品質の向上。既存システム基盤からのマイグレーション、新規立ち上げ事業の円滑化。
-

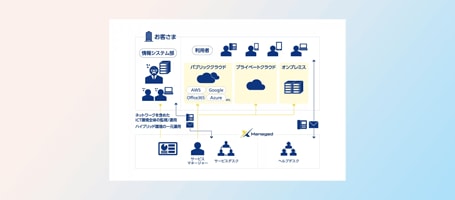
国内外ネットワークの一元管理でグローバルビジネスを加速
- トータルマネージドソリューション
- ネットワーク一元管理
- セキュリティ対応の自動化
監視システムの自動化による人為ミス削減、業務負荷軽減。複雑な監視運用の差異、優先順位のヒアリングをもとにした構成整理による監視漏れの防止、監視対応品質の統一。大規模監視に対応した短期チューニングによるスピーディーな導入を実現。
-

【事例】Dashboardの活用によってオペレーターの定着率や品質を向上
- コンタクトセンターKPI管理ソリューション
- 分析結果の視覚化
- 顧客満足度の把握
従業員の定着率の向上。可視化された顧客の満足/不満足度情報が顧客満足度の向上に貢献。オペレーターの品質のばらつきをサポート。自動分析によりスーパーバイザーの稼働をカバー。
マンガdeウィズICT

ICT環境の構築・監視・運用管理までワンストップでアウトソーシングする「トータルマネージドソリューション」について、その特長をマンガで楽しく解説します。
★★ 2024.09 リニューアルOPEN! ★★
4つのジャンルから選んで探せる検索機能を追加し、希望に合うマンガを簡単に見つけられるようになりました。
新着作品
-
マネージド・サービス/クラウド導入

クラウド運用からDatadogの監視運用までお任せ、PoC実施で導入準備も安心です
マルチクラウドマネジメント
みんな仲良し、アニマルランドに新しい仲間が加わった!監視ツール「Datadog」について詳しく教えてくれて、頼もしい限り。
-
ネットワーク監視・モニタリング

ネットワーク通信量を可視化し、機械学習による異常検知でネットワーク運用・分析をサポート
ネットワーク・トラフィック分析
毎日大忙しのアリンコカンパニー。最近導入した「ネットワーク・トラフィック分析」サービスについて、女王アリから質問されたIT担当アリは困ってしまい・・・?
-
セキュリティ対策

NGAV・EPP・EDRを統合し、自律型AIを駆使した次世代サイバーセキュリティ
SentinelOne
ジャスミン刑事のもとへ、宿敵・エージェント01から組織への復讐に関する協力依頼のメールが・・。仲が悪いはずの2人で共同作戦、果たしてどうなることやら!?
マネージドサービスとは

-

マルチクラウドとは?
メリットや進め方について解説マルチクラウド戦略とは、複数ベンダーのクラウドサービスを組み合わせて活用するITインフラ戦略のことです。近年、クラウド活用が進む中で、単一ベンダーへの依存リスクを回避し、柔軟性や安定性を高めるために注目されています。
日本でも生成AIやメタバースなどのデジタル革新が進む一方、企業のDX推進においては、データの利活用やクラウドインフラの最適化が重要課題となっています。
そこでこの記事では、「マルチクラウドとは何か?」という基本からメリット・デメリット、戦略策定のポイント、実践ステップまでをわかりやすくご紹介いたします。
-

ネットワークトラフィックが増加する原因や対策方法について解説
ネットワークトラフィックとは、社内外のシステム間でやり取りされる通信データの総量を指します。
デジタル化が進む現代のビジネス環境においては、トラフィックの増加が企業のネットワークのパフォーマンス低下やセキュリティリスクの要因となるケースが少なくありません。
この記事では、「ネットワークトラフィックが増加する原因」と「その対策方法」について、企業の情報システム部門が知っておくべきポイントをご紹介いたします。
-

マネージドサービスのメリット・デメリットとは?
フルマネージドサービスとの違いも解説マネージドサービスとは、企業のICTインフラの運用・管理を外部の専門業者に委託するサービスのことです。
マネージドサービスは、特に情報システム部門が運用にかけるリソースを削減し、業務効率化を図る手段として多くの企業に採用されています。
ただ、マネージドサービスにはメリットだけでなく、デメリットも存在します。
-

マネージドサービス導入の
5つのポイントとは?マネージドサービスとは、企業のICT運用を外部の専門業者に委託することで、コスト削減や効率化を図るためのサービスです。
多くの企業がICTリソースの最適化を目的に、このサービスの導入を検討しています。
しかし、マネージドサービスの導入に際しては、慎重に判断すべきポイントがいくつかあります。
-

マネージドサービスの活用方法とは?
企業が知っておくべきノウハウを徹底解説マネージドサービスは、企業 の情報システム部門にとって、ITインフラの運用負担を軽減し、コア業務に集中するための効果的なソリューションです。
ただし、サービスを最大限に活用するためには、その仕組みやメリットを理解し、適切な導入と運用する必要があります。
そこで本記事では、マネージドサービスの基本的な活用方法から、成功に導くためのノウハウについて、解説します。
-

マネージドサービスの
よくある失敗パターン10選マネージドサービス導入における主な失敗パターンは、次の10点です。
- 目標設定があいまいだった
- 現状分析が不十分だった
- ベンダー選定が不適切だった
- 柔軟性の低いサービスを選んでしまった
- 提供事業者とのコミュニケーションが不足してしまった
- 社内体制に不備があった
- 契約内容への理解が不足していた
- セキュリティ対策を軽視していた
- 変化に対する社内の抵抗感が強かった
- マネージドサービスへ過度に依存してしまった
マネージドサービスは、企業 の情報システム部門にとって、ITインフラの運用負担を軽減し、コア業務に集中するための効果的なソリューションです。
ただし、マネージドサービスについてよく理解していないと、導入に失敗する可能性も考えられます。そこで本記事では、マネージドサービスの導入においてよくある失敗パターンを10例、ご紹介します。同じ失敗をしないよう、参考にしてみてください。さらに、導入時に気をつけるべきポイントについてもお伝えします。
-

人材不足の解消に役立つマネージドサービスとは?
活用するメリットを解説マネージドサービスは、企業が抱える人材不足、特にIT分野の人材不足を解消する上で非常に有効な手段の一つです。
ただ、マネージドサービスを導入したことがない企業にとっては、どのように人材不足に役立つのか、具体的なイメージが沸かないかもしれません。
そこで本記事では、なぜマネージドサービスが人材不足に役立つのか、その理由と具体的な活用メリットについて解説します。
-

情シス運用におけるマネージドサービスの主なメリットとは?
導入する際のポイントや注意点を解説マネージドサービスは、情シス運用を効率化し、企業のICT環境を最適化するために最適なサービスです。
昨今、多くの企業で情シス部門が限られたリソースの中で急速な技術進化やサイバーセキュリティ対策に対応しなければならないという課題が浮き彫りになっています。
こうした背景から、専門的な知識とサポートを提供するマネージドサービスの活用が注目されているのです。
本コラムでは、マネージドサービスを情シス運用に導入するメリットや、導入時の重要なポイント、注意すべき点について解説いたします。
-

データやシステムを守るためのセキュリティ対策とは?
行うべき理由や方法を解説データやシステムを守るためのセキュリティ対策には、
- パスワードの管理
- アクセスの制限や管理
- ソフトウェア・OSの適切なアップデート
- セキュリティ対策ソフトの導入
- 社内全体のセキュリティ意識の向上
などがあります。
サイバー攻撃は年々、高度化・巧妙化しており、また、内部不正による情報漏えいも増加しつつあります。もはやシステムのセキュリティ対策は情報システム部門だけの検討事項ではなく、経営課題の1つと位置付けられます。
そこでこの記事では、企業が行うべきセキュリティ対策の重要性や、具体的な方法について解説いたします。
-

セキュリティ対策をアウトソーシングするメリットや
依頼する会社の選び方を解説情報セキュリティ対策をアウトソーシングするメリットには、次のようなものがあります。
- 専門家にセキュリティ対策を依頼できる
- コア業務に集中できる
- 属人化を防止できる
セキュリティ対策のアウトソーシングは、専門知識を活用しながらコストやリソースの効率化を図る手法として注目を集めています。特に、情報漏えいやサイバー攻撃のリスクが高まる現代では、セキュリティ専門会社に依頼することで企業の安全性を向上させることが可能です。
この記事では、セキュリティアウトソーシングの利点や、適切な依頼先を選ぶ際のポイントについて詳しく解説していきます。
ICTコラム
-

プラットフォームとは?IT・ビジネスでの意味や種類、具体例を解説
「プラットフォームとは」という言葉は、ITやビジネスの現場で頻繁に耳にする用語です。しかし、その正確な意味や種類について、深く理解している人は少ないかもしれません。本記事では、プラットフォームの基本的な意味をはじめ、IT・ビジネス分野での役割、具体的な例までを分かりやすく解説します。
-

「サイバー災害」は他人事ではない!企業規模別対策を紹介
国内で相次ぐサイバー災害が、企業活動と社会インフラに甚大な被害をもたらしています。大手企業の事業停止や医療機関の診療停止、自治体業務の麻痺など、その影響は自然災害に匹敵すると言えるでしょう。しかし、サイバー災害は自然災害とは異なり、従来のBCPでは防ぎ切ることができません。本記事では、企業規模別のサイバー災害対策を解説します。
-

SaaSとは? 導入メリットや安全・快適な使用方法について
通信環境の高速化、大容量化に伴い、ソフトウェアはパッケージで購入する時代からダウンロードする時代へと移行しました。そして現在は、さらにソフトウェアをインストールすることなくサービスとして利用する「SaaS」への移行が始まっています。SaaSには、コスト削減、運用管理業務の効率化などさまざまなメリットがあり、製造業、小売業、サービス業など多種多様な業界においてDX化を実現する切り札としても期待されています。
-

MSSPとは?MSPやMDRの違いや導入のメリットについて解説
昨今、中堅・中小企業を端緒としたサプライチェーン攻撃が増加しています。代表的なのは、大企業と比べてセキュリティ対策の甘い中堅・中小企業のネットワークに侵入し、そこを足掛かりとして取引先の大企業に侵入して情報剽窃やランサムウェア攻撃を行う、いわゆる「ラテラルムーブメント」と呼ばれるサイバー攻撃手法です。知らぬ間にとはいえ、踏み台にされた以上、自社の責任は免れません。被害がサプライチェーン全体に及ぶ場合や、長期間にわたって生産ラインが停止する場合なども想定され、自社だけでは到底埋め合わせできないような被害を生む危険性があります。そこで現在、「MSSP」と呼ばれる、企業や組織のセキュリティ対策を外部の専門会社に委託するサービスが注目を集めています。今回は、このMSSPについて、導入するメリットやサービスの詳細について解説します。
-

Cloud Adoption Framework(CAF)とは?成功するクラウド戦略の実践ポイント
近年、企業にとってクラウド導入は必須の取り組みの1つとなりつつあります。DXを推進し経営変革を図る上で、クラウドシステムの利便性や効率性が不可欠な要素となっているからです。
-

マルチベンダーとは?導入のメリット・デメリットや運用手順を解説
マルチベンダー体制を検討する中で、「コストや機能面では魅力的だが、運用が複雑になりそう」「ITベンダー間の調整や責任分界が不安」と感じている方もいるでしょう。複数のベンダーを組み合わせることで柔軟なシステム構成が可能になる一方、管理負荷やトラブル対応の難しさに悩むケースは少なくありません。
-

-

AIセキュリティとは?AI活用によるリスクや企業ができる対策を解説
ゼロトラストは「信頼を前提にしない」考え方ですが、導入範囲が広く、何から手を付けるべきかでつまずきがちです。従来型の境界防御とは異なり、考え方や進め方を誤ると、業務影響や運用負荷が大きくなります。ネットワークを一気に置き換えるよりも、守る対象と現状の課題を整理し、全体像を描いてから優先度の高い領域へ段階的に広げるほうが現実的です。
-

セキュリティのCIA(3要素)とは?対策例でわかる機密性・完全性・可用性
情報セキュリティ対策の土台となる考え方が「CIA」です。セキュリティとは何かを理解する上で欠かせないこの概念は、米国の諜報機関のことではなく、「機密性(Confidentiality)」「完全性(Integrity)」「可用性(Availability)」という3要素の頭文字を取ったものです。この記事では、情報セキュリティのCIAとは何か、それぞれの要素が何を意味するのかを具体的な対策の例を交えながら解説します。
-

リファクタリングとは?コードの目的やメリットをわかりやすく解説
IT分野におけるリファクタリングとは、ソフトウェアの外部的な振る舞いを変えずに、内部のコードを改善する作業を指します。本記事では、リファクタリングの目的やメリットについて、日本語で簡単に解説します。動いているコードをなぜわざわざ修正するのか、その必要性や具体的な進め方について理解を深めることで、より品質の高いソフトウェア開発を目指せます。
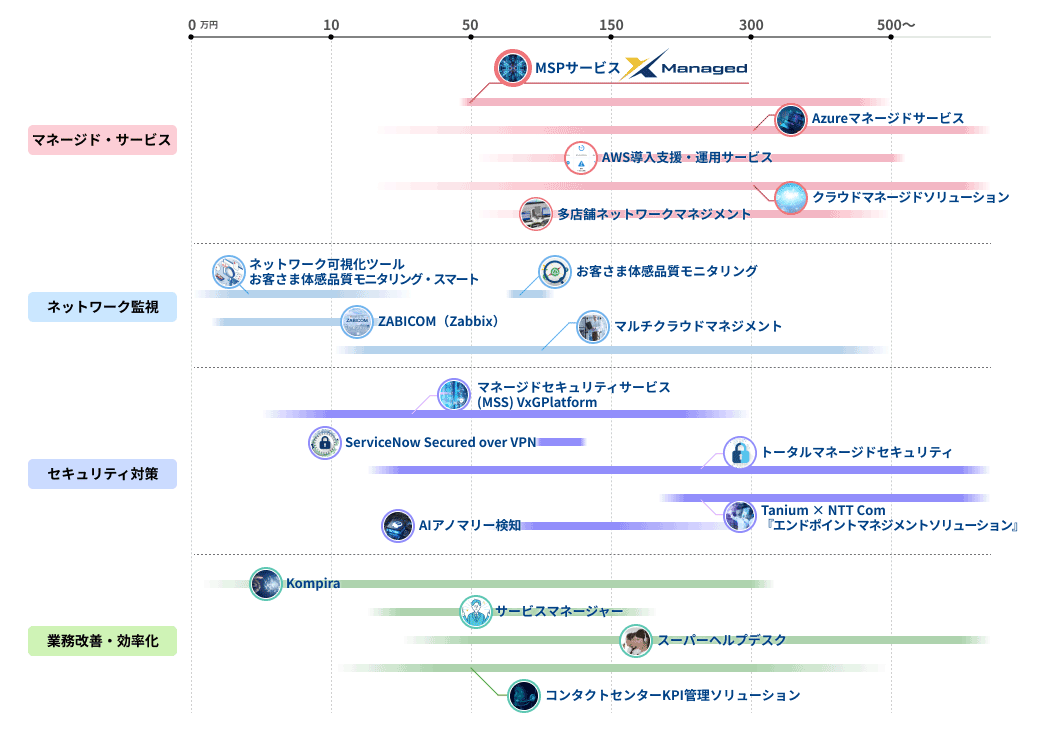
サービスマップ
各サービスをクリックすると、それぞれのサービスページへと移動します。
左右にスクロールしてご覧ください。
月間コスト
サービスメニュー
各サービスをクリックすると、それぞれのサービスページへと移動します。
左右にスクロールしてご覧ください。
マネージド・特性マップ
| オールインワン・コンポーザブル | カスタマイズ | ワンストップ |
|---|---|---|
|
網羅的に機能を揃え選択によって最適化とコスト的成果を実現 |
網羅的に機能を揃え選択によって最適化とコスト的成果を実現 |
要件定義から構築、そしてマネージド提供まで一気通貫で提供 |






個別ソリューション・特性マップ
| 監視・可視化 | セキュリティ | 自動化 | 管理 | |
|---|---|---|---|---|
| ネットワークのパフォーマンスやトラフィック監視 | 閉域ネットワーク・AIを使ったセキュリティ対策 | Tier1のシステム運用自動化 | オープンソースの統合管理、サービスの請負管理 | |
| 自社SW導入 (ツール) |
||||
| 導入運用 サポート |
||||
| 運用請負 |