


AIにおける2026年問題とは?
AIにおける2026年問題とは、AIの一種であるLLM(Large Language Model、大規模言語モデル)が学習に使用する高品質なテキストデータ(正しい文法で書かれたテキストデータ)が2026年に枯渇してしまうという予測を指します。
2026年問題が広く知られるようになったきっかけは、AIの権威であるスチュアート・ラッセル氏(Sir Stuart Jonathan Russell、サー・スチュアート・ジョナサン・ラッセル)が2023年に開催された「AI for Good Global Summit(AIサミット)」のインタビューにおいて、「これまで、LLMはモデルを巨大化し、より多くの学習データで訓練することに依拠してきたが、個人的にはその流れは終わりを迎えつつあると考えている」と発言したことにあります。
同氏は続けて、「正確に把握することはできないが」と断りつつも、「GPT4の作成には、Web上に公開されているすべてのテキストデータに加え、非公開の文書データも使用された。その総量は人類がこれまでに書いたすべての書籍の量に匹敵する」と述べました。
参考:「ITU INTERVIEWS: Stuart Russell」(英語)
※ITU:国際電気通信連合 (International Telecommunication Union)
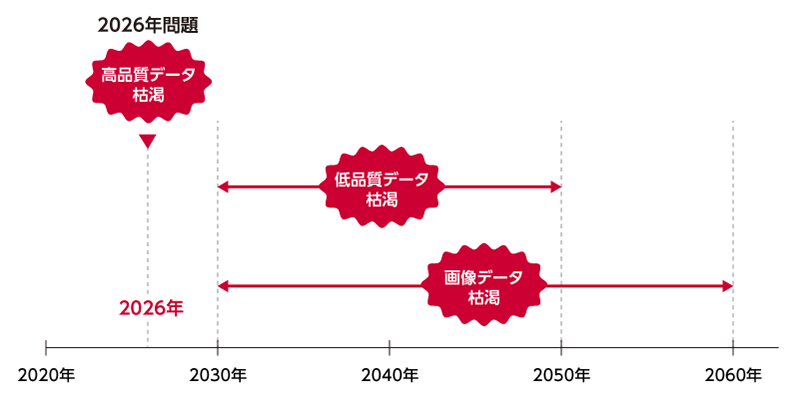
実際に、AIの進化と現状の課題を調査する研究機関である 「EPOCH AI」が2022年に公開した予測によると、高品質なテキストデータは2026年までに、低品質なテキストデータ(ブログやSNSなど、一般の人々によって書かれた、くだけた言い回しや文法上の不正確さを含むテキストデータ)は2030年から2050年までに、そして画像データも2030年から2060年までに枯渇すると予測されました。
LLMはAIの一種で、NLP(Natural Language Processing、自然言語処理)技術により人間の言葉を理解します。LLMを構築するためには大量の学習データが必要です。学習データにはデータと解答が1対となった「教師ありデータ」、データのみの「教師なしデータ」の2種類があります。
例えば「猫と犬を見分けるAI」を構築する場合は、猫の写真と「猫」というラベルがセットになったデータおよび犬の写真と「犬」というラベルがセットになったデータ、つまり「教師ありデータ」を学習データとして与えれば精度の高い分類を行うことができます。しかし、言語のように明確な正解がないものを処理させる場合には「教師なしデータ」を使用し、人間の脳の神経回路を模したニューラルネットワークによりディープラーニング(Deep Learning、深層学習)を行い、言語のパターンを認識させます。教師なしデータで学習を行うためには、教師ありデータよりも大量の学習データが必要となります。そこで、初期のLLMは「クローラー※」により収集された学習データを使用していました。
※クローラー:Webサイトを自動巡回し、情報を収集するプログラム。
しかし、より洗練された学習を行うためには、Web辞書や大手ニュースサイトの記事など、正しい文法で書かれたテキストデータ、すなわち「高品質なテキストデータ」が重要となります。一般の人々が書いたブログやSNSなどの文章には、乱暴な言葉が使われていたり、文法が誤っていたりといった、いわゆる「低品質なテキストデータ」が含まれる場合があるためです。
以上のような背景から、2026年問題が注目されることとなりました。
ちなみに、物流業界にも「2026年問題」がありますが、こちらは2026年度に施行される予定の「物資の流通の効率化に関する法律」に伴いDX化が急がれるという問題であり、AIの2026年問題とはまた別のものです。
データが枯渇するとAIの進化は止まってしまう?
2026年問題により学習データ、特に「高品質なテキストデータ」が枯渇すると、LLMの進化が滞ってしまう恐れがあります。対話型のAIや文書を生成するAIは急速に進化を遂げ、現在ではさまざまな業務に利用できるほどの品質となりましたが、今後このペースでの進化が難しくなる危険性があります。
前述のスチュアート・ラッセル氏も、同インタビュー中で大量の学習データを利用したGPT4ですらまだ能力は十分でない、と発言しており、これは由々しき問題です。
また、先に紹介したEPOCH AIの記事においても、これまでは「計算能力」がAIの能力向上のボトルネックとなっていましたが、2026年以降はデータの枯渇がボトルネックになる可能性がある、と警鐘を鳴らしています。
さらに不足した学習データを補うために著作権で保護されたテキストデータや個人情報の含まれるデータを権利者に無断で使用するケースが増加する危険性もあります。現在のように過度なAI開発競争が行われる中で2026年問題に直面した場合、技術的な問題のみならず社会的な問題も引き起こしかねない危険性があるのです。
ただし、これらは将来にわたって学習データの利用効率に革新的な変化が起こらないという、ある意味非現実的な仮定にもとづいたものであることに注意が必要です。
現在は確かに新たなテキストデータの供給を上回る勢いで学習データとしての消費が行われていますが、今後、新たなテキストデータを供給する仕組みが構築される、効率的な学習データの活用技術が開発される、などの技術革新が起こった場合には、2026問題は先送りになる、あるいは解決できる可能性があることは2022年時点においてEPOCH AIが記事中で言及しています。
2026年問題の解決策はあるのか?
現在、2026年問題の解決に向け、効率的な学習データの活用、新たなテキストデータ供給に向けた試みが続けられています。
効率的な学習データの活用という観点からは、低品質なテキストを含む大量のデータを用いた学習から、厳選した高品質なテキストデータのみを使用する学習への転換が試みられています。スチュアート・ラッセル氏の「LLMモデルの巨大化は終わりを迎えつつある」という言葉を受け、少規模で特定の目的に特化したSLM(Small Language Model、小規模言語モデル)が注目されています。
具体的には、新聞社や出版社といった、編集作業を経た高品質なテキストデータを保有する企業と提携し、これまで学習データとして利用できなかったテキストデータを学習に活用することで、効率的にタスクをこなせるSLMを構築しようという試みです。
2024年末、中国企業のDeepSeek社が無料で使用できる生成AIを公開し、大きな話題となりました。巨額の予算をつぎ込み開発された先行AIと比較しても性能が引けをとらなかったことに加え、特に開発予算が先行企業の100分の1以下程度であったこと、開発期間が数カ月と非常に短かったこと、比較的性能の低いGPUを利用していることなどが注目されました。同AIにはさまざまな疑惑が持ち上がっており詳細は不明ですが、SLMの可能性を示した1事例といえるでしょう。
また、新たなテキストデータを供給する仕組み作りへの取り組みとしては、「合成データ(Synthetic Data)」の活用があります。
「合成データ」とは、生成AIで生成した、実世界のデータに似せた学習データを指します。ゼロの状態から生成する「完全合成データ」と、実データの一部分を生成データに置き換える「部分合成データ」の2種類がありますが、どちらも「無制限にデータを生成できる」「個人情報保護の問題が生じない」「データ収集者の個性やデータ収集手法によるデータの偏りが生じない」などの利点があります。
合成データ自体は2010年代から敵対的生成ネットワーク(GAN:本物の画像と生成した偽物の画像を見分けることで学習するネットワーク)で偽画像の生成に活用されてきました。テキストデータについても、2020年代から活用が進んでいます。
合成データは今後、特に医療分野や金融分野など、秘匿性の高い分野での活用が期待されています。
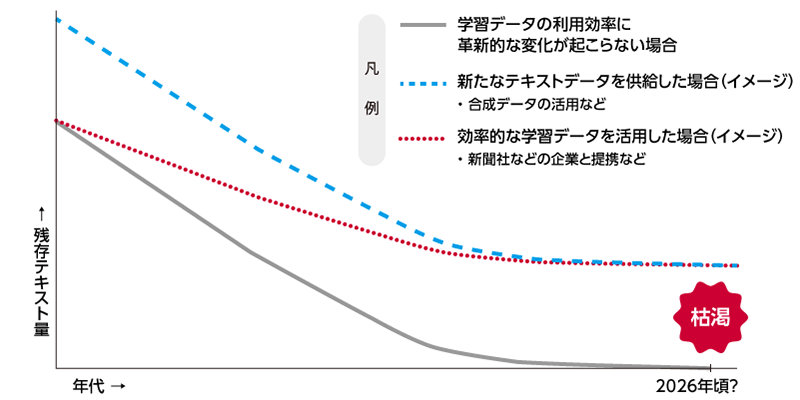
実は、EPOCH AIは2024年に2022年の予測を更新しています。それによれば、高品質なテキストデータの枯渇は2026年から2032年の間に枯渇されると予測されており、やや後ろ倒しになりました。
EPOCH AIはその理由として、「Web上のデータもうまくフィルタリングすることで高品質データとして利用可能であることが分かったため、残存するテキストデータの量が5倍に増えた」、「同じ学習データを複数回利用してもAIの性能の劣化が見られなかった」などをあげています。
ただし、この分析には合成データの影響は含まれていません。同記事では、2030年以降も現在のペースでAIの進化を継続するためには、合成データの利用、テキストデータの利用効率の向上、テキスト以外の学習データの活用などが必要だと結論付けています。
また、現在では特定の目的に特化したSLMの開発も急ピッチで進められています。
今や、AIは私たちの暮らしになくてはならない存在となっています。特にユーザーとのやりとりを通じて能動的に業務を自動化できる「AIエージェント」は、カスタマーサポートやチャットボット、音声アシスタント などに活用されるなど、業務での利用シーンも増加しています。将来的にはAI利用の9割以上をSLMが担うのではないかとの予測も出ています。
まとめ
現在、2026年問題の解決に向けて、「新聞社や出版社といった、編集作業を経た高品質なテキストデータを保有する企業と提携する」「生成AIが生成した合成データを活用する」などの取り組みが進められていますが、このままのペースでテキストの消費が続けば2026年問題は現実のものとなります。
これまでにもAIの開発には紆余曲折がありました。1950年代にAIの概念が生まれてから、1970年代には人間のモデル化の困難さから性能向上が停滞し冬の時代を迎え、また2000年代には人海戦術により大量の学習データを用意することの困難さからふたたび冬の時代を迎えました。2度の冬の時代を迎えても歩みを止めなかったAIの進化ですから、現在とは形は変わるかもしれませんが今後も進化は続いていくことでしょう。2026年問題の早期の解決が待たれるところです。





