





AIの性能を左右する「データの品質」
私たちFastLabelは、「教師データ」を軸に事業を展開しています。教師データとは、AIに正解を教えるためのデータのことです。
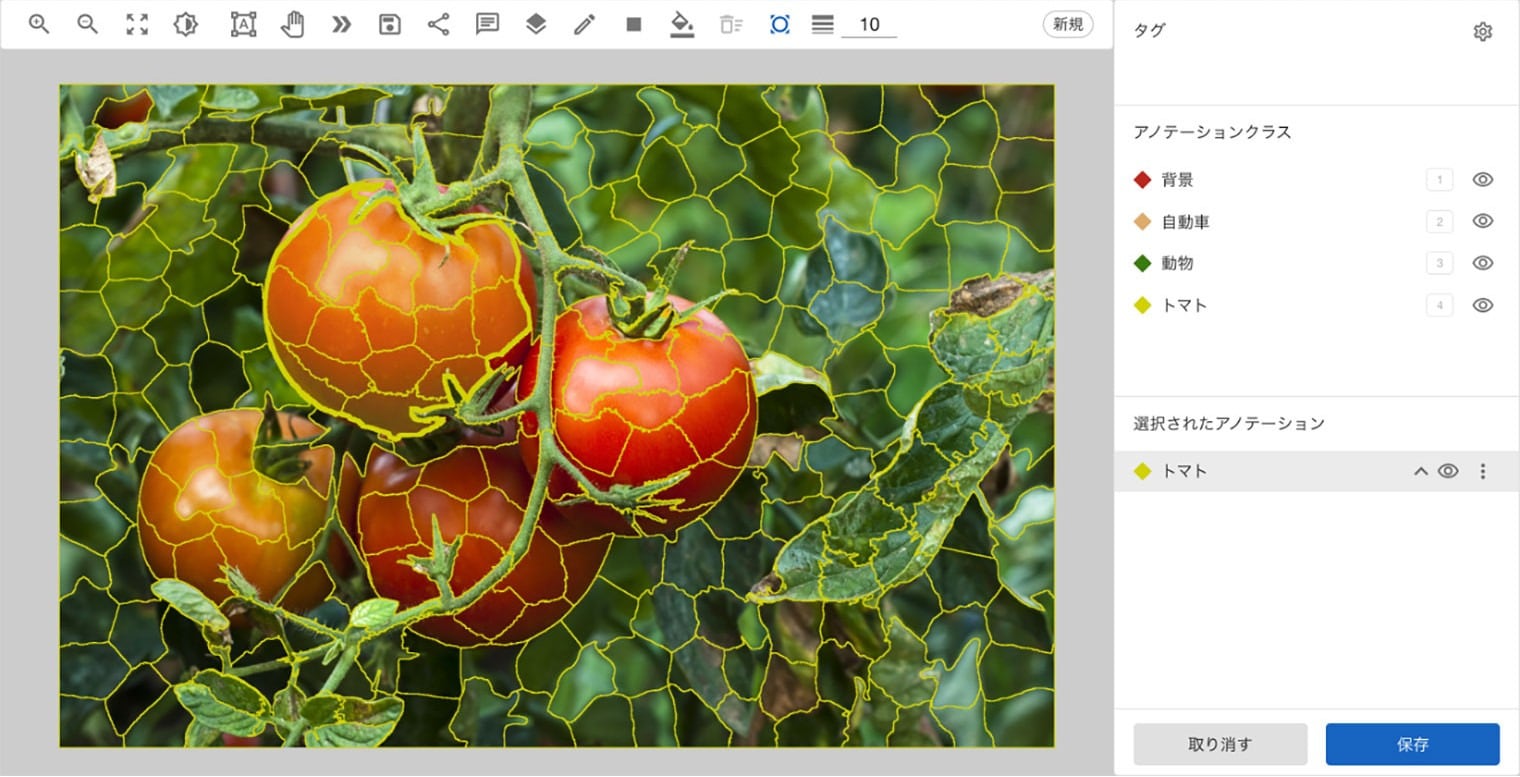
例えば画像認識AIの場合、写真に「ここに車があります」「ここに人がいます」といった正解ラベルを付ける作業によって、AIが新しい写真を見たときに対象物を自動的に判断できるようになります。
ラベル付け(アノテーション):画像などのデータに「これは○○です」といった印を付ける作業のこと。AIが正しく学習するために不可欠。
基本的にAIは「データ」と「アルゴリズム(処理手順)」の2つでできています。ですから、質のいいデータを大量に用意すれば、アルゴリズムを変えなくてもAIの性能が大幅に向上します。

これを「データセントリックAI(Data-centric AI)」と呼びます。従来のモデル(アルゴリズム)中心の開発手法に対し、データの品質向上を重視するアプローチのことです。
つまり、アルゴリズムに手を加えなくても、いいデータを集めることでAIを賢くできるのです。私たちはここに特化してAI開発を支援しています。
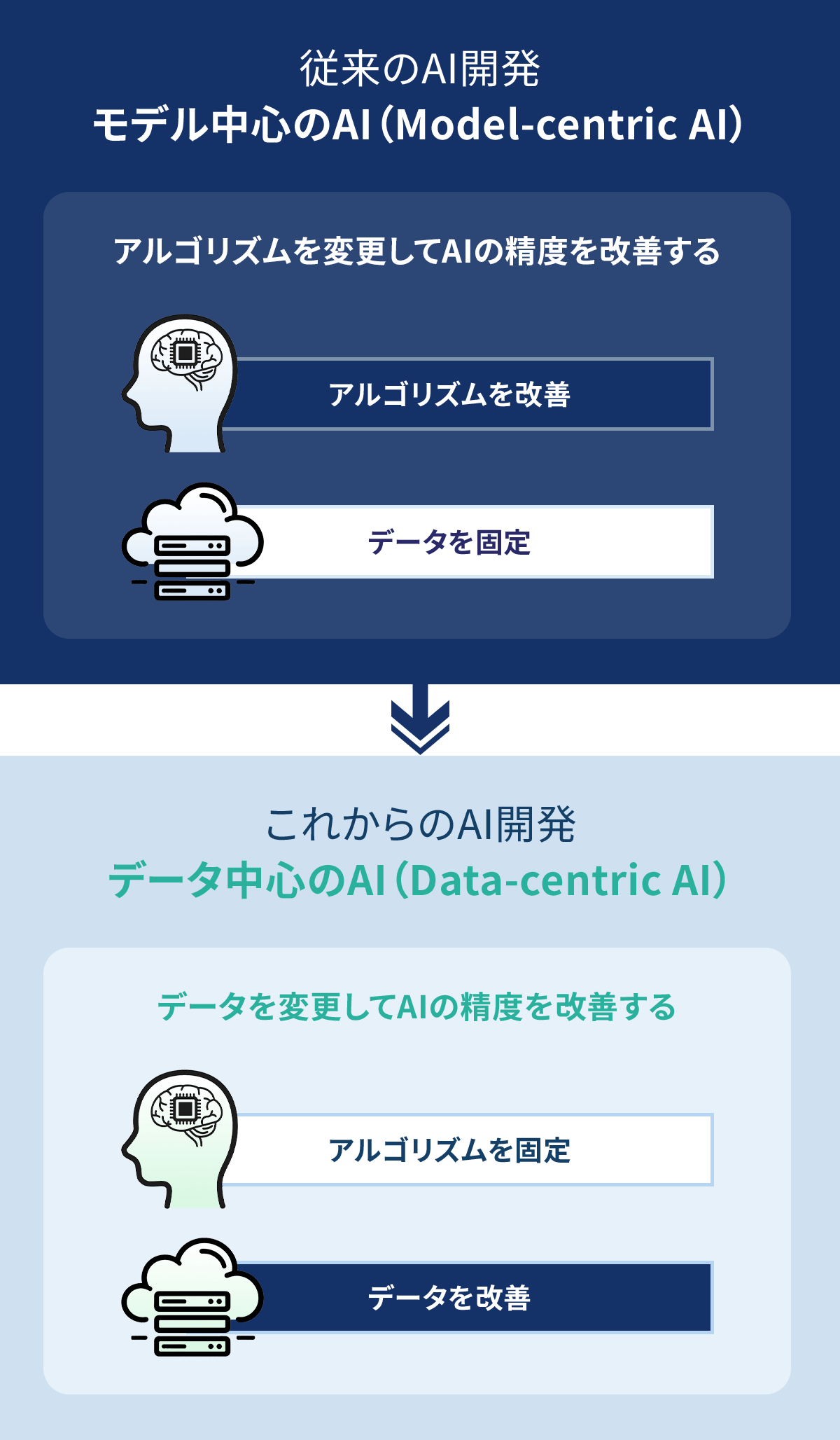
データの品質がAI性能にどれだけ影響するか、わかりやすい事例があります。
AI研究で有名なスタンフォード大学のアンドリュー・ング兼任教授が鋼材の欠陥検出AIの実験で示したところによると、モデル中心のアプローチ(プログラムやアルゴリズムの改善)では精度向上が0%だったのに対し、データ中心のアプローチ(データの品質改善)では約17%もの精度向上を実現しました。
つまり、AIを賢くするには高品質なデータが何より重要だということです。これはAI開発になじみのない多くの人々にとって、意外な結果かもしれません。
誰もやりたがらない仕事を、テクノロジーで効率化
この教師データづくりの分野は従来、完全に手作業で行われていました。大企業でも、データ作成のやり方がバラバラで属人的、組織的なルールもない状況でした。
そのため作業は外注されていましたが、人手に頼るビジネスなので、従来の業務代行(BPO)企業が参入するケースが多かった。
ところが、AIの知識がなく自動化のノウハウもない企業が多く参入してきたため、大企業が依頼しても品質が安定しないという問題がありました。
そこで、データ作成を効率化する「FastLabel Data Factory」というシステムを開発しました。
お客様から預かったデータに、私たちが正確なラベル付けを行い、高品質なデータを効率よく作成してお客様にお渡しします。そのデータでAIを学習させれば、性能が向上します。

正直、データ作成は本当に誰もやりたがらない地味な仕事です。しかしFastLabelはテクノロジーを活用して、この作業を高い生産性で効率化しています。
創業した頃は自動化技術もなかったので、最初は人手で作業していました。
データ作成は大人数で作業することが多いのですが、人によってラベル付けの判断基準がブレてしまい、バラバラなデータができてしまう。結果としてAIが混乱して学習がうまくくいかず、性能が上がらないという問題がありました。
そこで厳格なルールを整備し、質の低いデータが混入しないシステムを構築しました。ツールやプロセスを進化させ続けた結果、現在は非常に安定した品質でデータ作成ができるようになっています。
画像、テキスト、動画などさまざまなデータを扱いますが、それぞれにルールを整備しています。経験を積むことで、どんなプロジェクトでも品質を安定させることができるようになりました。
具体的な成功事例をご紹介しましょう。お客様でトマトの収穫ロボットを開発している企業があります。私たちが高品質な教師データを作成したところ、AIの認識精度が約30%も向上しました。
それまではトマトをうまく認識できず、思うように収穫できていませんでした。しかし、データの品質を向上させたことで、ロボットが正確にトマトを見つけて収穫できるようになったのです。これがデータの力です。
国産の生成AIモデル開発には教師データが鍵となる
FastLabelは2020年に創業し、ChatGPTなどの生成AIがブームになる前からAI開発の支援をスタートしています。
当初は、画像や音声を認識する「認識AI」が主流でした。工場の検査システムや防犯カメラの人物検知などに使われるAIです。そこに向けてサービスを提供することで、事業も成長していきました。
ところが生成AI登場後、サービスを活用する顧客層が大きく変わりました。従来の製造業や小売業より、ChatGPTの基盤技術でもある大規模言語モデル(膨大な文章データを学習して自然な文章を生成するAI)や、日本語に特化した生成AIを開発している企業が、だんだんとメインカスタマーになってきました。

いまは画像、音声、テキストなど複数のデータを同時に扱う「マルチモーダル化」が進み、あらゆる種類のデータが必要になっています。
さらに、日本語のデータは世界的に見て圧倒的に少ないという課題もあります。現在のお客様は主に日本の大企業ですが、汎用的なAIモデルや特化したAIモデル開発に必要なさまざまな教師データをつくっています。
FastLabelのサービスを導入していただくケースの多くは、現場からのボトムアップです。
経営陣から何か具体的に指示された結果ではなく、現場の担当者が「このプロジェクトにはこんなデータが必要だ」と調べたり考えたりしたうえで、具体的な相談を受けるケースが大半です。
特に生成AI関連では、独自の日本語AIモデルを開発している企業が中心になっています。しっかりと予算を確保し、本格的な取り組みとしてデータ作成を依頼されることが多いです。

データの力で、より多くの企業にAIを
サービスを続けていく中で、新たな課題も見えてきました。データの管理です。
最初は「FastLabel Data Factory」でデータ作成の効率化だけを考えていましたが、作成したデータがどんどん蓄積されてくると、管理が複雑になってきました。
「どのデータをどのAIモデルで学習させたのか」「品質に問題があるデータはいつつくられたものか」「どのデータを修正すれば性能が向上するか」といったことを追跡する必要が出てきたのです。データは常に追加されるため、時系列での管理も必要です。
大企業では事業部ごとに導入されることが多く、部署ごとに異なるデータが蓄積されていきます。また、古くて質の悪いデータを除去したいケースもあり、きちんと追跡できるシステムが必要でした。
例えば、画像認識AIでカメラの人物検知精度を上げたい企業では、データを徐々に蓄積していきます。AIの性能向上に伴ってより多くのデータが必要になり、管理の複雑さが爆発的に増大します。

そうした企業から、データ管理機能の導入を求められるケースが増えています。
このように、AIの導入が進むにつれて、データ作成だけでなくデータ管理も重要な課題となってきているのです。
私たちは「誰もやりたがらない仕事」から始まりましたが、いまやAIの心臓部とも言える最も重要な部分を担っています。
データの品質がAIの性能を決める以上、その役割はますます重要になっており、大企業だけでなく、より多くの企業がAIを活用できる環境をつくっていきたいと考えています。
この記事はドコモビジネスとNewsPicksが共同で運営するメディアサービスNewsPicks +dより転載しております。
執筆:加藤智朗
撮影:大橋友樹
バナーイラスト:Triangle_c / gettyimages
図版制作:WATARIGRAPHIC
デザイン:山口言悟(Gengo Design Studio)
編集:奈良岡崇子





