



小規模な言語モデルだからこそ、できることがある
「LLM」という言葉を、ビジネスシーンで聞いたことがある人は多いかもしれません。LLMとは、ヒトの脳の動きを模した機械学習モデルであるニューラルネットワークを用いて文章を生み出す仕組みの一つであり、ユーザーが入力した質問を理解し、回答するための技術です。Large Language Modelsの略語であり、日本語では「大規模言語モデル」と表されます。
LLMは、膨大な量の文章を学習しているため、まるで人間が文章を書くように、自然な文章を出力することが可能です。たとえば会議のリアルタイムな文字起こしや要約、メール文案の作成など、ビジネスシーンにおけるさまざまな業務で活用できます。
このLLMに似た言葉として、「SLM」というものも存在します。SLMとは「小規模言語モデル(Small Language Models)」のことで、LLMと比較するとモデルとしての規模は小さいものの、そのぶん動作は早く、かつデータ容量も軽いという特徴があります。
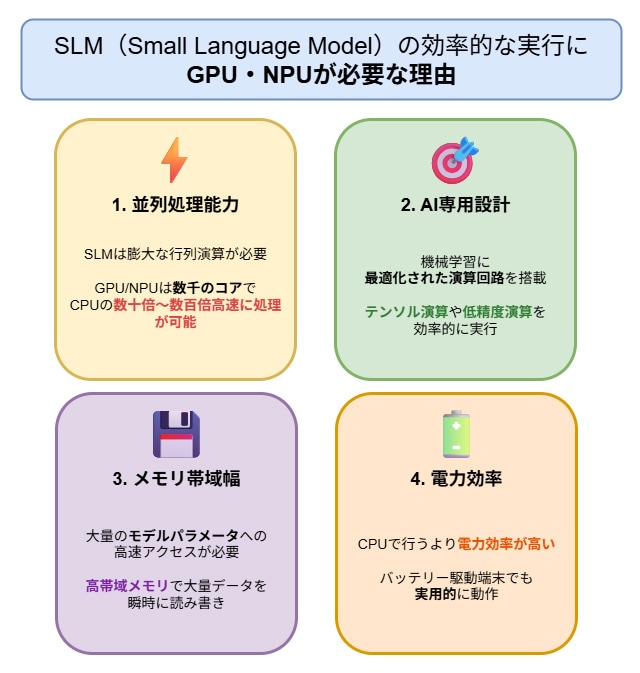
この特徴から、大規模なデータセンターや高性能なGPU(※1)を搭載したワークステーションを必要とせず、小規模なGPUやNPU(※2)を搭載したラップトップPCやスマートフォン上でも実行できるため、オフライン環境でも利用できるというメリットがあります。そのため機密情報を入力しても、その情報がクラウドに送られることはなく、学習データとして知らぬ間に利用される心配もありません。
(※1)GPU:もともとは画像処理用に作られたチップで、AIの大量計算に強いという特徴を持つ。GPUは「Graphics Processing Unit」の略。
(※2)NPU:AIを高速に処理するための専用チップのこと。NPUは「Neural Processing Unit」の略。
SLMはこうした「早い/軽い/安全」という特徴から、ノートPCに付属の生成AIとして搭載されたり、医療や金融といったプライバシーが重視される環境で活用が始まったり、徐々に導入が進みつつあります。
SLMはビジネスの形をどう変える可能性を秘めているのでしょうか?そして、SLMを導入するにはどうすれば良いのでしょうか?SLMの活用プラットフォームを提供する、株式会社日本AIコンサルティング チーフデータサイエンティストの新居桂陽氏に話を聞きました。
ビッグテック企業がLLMを高性能化。
でも必要以上に賢くなる必要はない?
――まずは新居さんが所属している日本AIコンサルティング社がどのようなビジネスを行っているのか、簡単にご説明いただけますか
我々日本AIコンサルティングは、企業のAIの導入や活用を支援し、ビジネスにおける業務効率化や付加価値向上をサポートする会社です。
最近では、従業員数が数名程度の企業やチームを中心に、クラウドに接続しないローカル環境で生成AIを利用したいというニーズが増えています。当社はそういったような企業に対し、小さなモデルの生成AI、いわゆるSLMを手軽に活用できるプラットフォームを提供しています。また、このプラットフォームを用いたアプリ開発サポート及び導入支援をおこなっています。
――今回はSLMの活用法についてお話を聞きたいのですが、その前段階として、まずはLLMがビジネスシーンにてどのように使用されているのか教えてください
やはりLLMはOpenAIやGoogleなど、資金力に優れるビッグテック企業が強いです。これらのビッグテックは、最先端の生成AIモデルを開発し、それをクラウド上でWebサービスとして提供し、マネタイズを進めようとしている戦略が目立ちます。
ビッグテックが提供している生成AIは、テキストも画像も音声も扱え、それらの入力・出力もできる「マルチモーダル」が当たり前となっています。加えて、長い文脈、長いテキストの処理に対応することもデフォルトです。たとえばGoogleの生成AI「Gemini」では、100万トークン(※1)もの長い入力に対応しています。たとえば、太宰治の「走れメロス」はおおよそ1万トークンくらいとされていますので、「Gemini」では走れメロス程度の資料をおよそ100冊分処理させることができるようです。
(※1)トークン:AIが文章を分解し、処理するための最小単位。文字数や単語数とは異なる。
これに加えて、「ファンクション・コーリング」(※3)や「MCP」(※4)などのようなツールを呼び出し、外部情報を利用するための仕組みに対応しているケースも多いです。たとえばユーザーからの質問に対し、生成AIが自分の知識では回答できない場合、Wikipediaなど外部のサイトを見る、といったように、生成AIが色々な外部情報を参照しながら回答する(RAG処理)ようなことが実現できます。
(※3)ファンクション・コーリング(Function Calling):生成AIが外部のツールや仕組みを呼び出して処理をする機能のこと
(※4)MCP:生成AIと外部サービスをつなぐ共通ルールのこと。MCPは「Model Contextual Protocol」の略
こういった生成AIに多様な情報を与えることで、正しい回答や望ましい出力を得る技術が発展しています。それに伴い、生成AI自体がすべてのことを正しく覚えるよりも、AIがRAG処理(※5)やファンクション・コーリングなどで外部情報を参照し適切な回答を生成する形で良いのでは、といった「モデル単体の賢さは、一定レベル以上あれば十分で、与えられた情報を適切に利用できれば実用に資するのではないか」と考えられ始めています。
(※5)RAG処理:AIが外部の知識やデータ を検索し、その内容を回答に盛り込むこと。RAGとは「Retrieval-Augmented Generation」(検索拡張生成)の略。
――現状、LLMはビジネスシーンにてどのような業務に使用されることが多いのでしょうか?
大きく2点に分類されると考えています。ひとつは社内のドキュメント作成のような定型業務です。具体的にいえば、会議の議事録作成や、コールセンターにおける通話内容の文字起こしなどです。いま我々が行っているようなインタビュー内容の文字起こしも、これに該当します。要は、人間がやると手間がかかり、面倒くささが感じられる定型業務で使用されています。
もうひとつが、生成AIを使ってさまざまなプログラムコードを書く作業です。プログラマーのみならず、プログラミングの経験が少ない、または全くないユーザーにおいても、生成AIに実現したいことを伝えることでプログラムを作成するコーディングの手法は「バイブコーディング」(Vibe Coding)と呼ばれています。バイブコーディングでさまざまなアプリケーションを作り上げ、その中から特に良いものを使っていくといった手法で、LLMは活用され始めています。
SLMは「小さな専門家」。
決して廉価版LLMではない
――LLMの概要については理解しました。それではSLMとLLMには、本質的にどのような違いがあるのでしょうか?
実は、本質的にはそこまで大きな差はありません。どちらもプロンプトを入力すれば、文字が出力される点は同じですし、多くの場合、「Transformer系」と呼ばれるモデルアーキテクチャで作成されています。
異なるのは、スケールが生むモデルの質です。モデル規模が大きければ大きいほど、学習で拾えるパターンが増え、見たことのない問題への一般化が働きやすくなります。結果として、長文での一貫性の確保や多段推論、ノイズ耐性が向上するので、未知の課題への一般化や長文の一貫性、多段の推論で優位に立ちやすく、様々な用途に対して汎用的に機能します。ただし代わりに計算資源と時間をたくさん使うことになります。
一方でSLMの場合は、端末での処理や低コスト運用といった制約の中で“必要十分”を狙う設計で、特定の業務や短い入力に対して機敏に働けます。ただし、適切な用途で用いないと日本語の文法が守れていないような文章や、ハルシネーション(※6)を返すことの多いモデルとなってしまう点には注意が必要です。
(※6)ハルシネーション:生成AIが事実とは異なる情報を回答してしまう現象
とはいえ、これはひと昔前の話ともいえます。現在では単体でも十分に機能するSLMが増えてきています。
――簡単にいえば、SLM はLLMの廉価版、“ジェネリック版LLM”といったようなところでしょうか?
少し前であればその認識で良かったのですが、最近ではそういう話ではなくなってきています。
最近のSLMは、学習データの質と手順が大幅に改善されました。特に、LLMという“大きな先生”から、蒸留学習(※7)というアプローチによって、コツを圧縮して学べます。
(※7)蒸留学習:大規模なモデルを教師として、より小さなモデルへ効率的に知識を移し替えること。Knowledge Distillationの略。
大きな先生側は「MoE」(Mixture of Experts)によって非常に大規模化し、かつ性能が向上しています。MoEを採用したモデルは、例えるなら“専門家の合奏”で、飛行機が複数のエンジンを並べて搭載し、出力を確保しているようなものです。1つのエンジンの出力はある程度限られますが、複数のエンジンを組み合わせれば、より大きな出力を得られます。MoEの成果が、蒸留学習という形でSLMに間接的に流れ込んでいます。
しかもLLMの場合は、多い場合は100近くあるエンジンのうち、適切な5つのみを用いて出力を得るようなことができるため、計算資源も効率的に利用することができます。こうした大規模で性能の良いLLMを教師とすることで、実用的なSLMが作成されるようになってきました。
加えて、SLMにおいては、軽量なモデル設計や量子化などで性能を維持しつつ、速く動くようになりました。実運用ではRAGやツール連携で知識の穴を埋められるので、SLMとしては、RAGやツール連携に特化した専門家として構築し、小さくても仕事で十分戦えるものを目指す方向性が見えてきています。要するに、良い教材+先生のノウハウ+設計の工夫+道具の使い方の総取りで、SLMは頼れる存在になりつつある、ということです。

クラウドを経由しないローカル環境でも、
生成AIが使える
――SLMはLLMよりも小規模ということは、たとえば中小企業での利用に向くということでしょうか?
おっしゃるとおり、SLMは中小企業での利用に向いている一面があるといえます。
SLMの特に良いところは、インターネットに接続されていない「ローカル環境」でも使えるという点です。ローカル環境であれば、どんな使い方をしたとしても、入力した内容はその端末に留まりますので、それはそのPC上でしか処理がされません。機密情報が流出するような、危険な状態にはなりにくいです。
さらに、たとえば災害時に停電が発生し、インターネットが使えなくなったり、クラウドサービス側のサーバーが落ちたりしたとしても、ローカル環境で動作する生成AIがあれば、クラウドへの接続は不要のため、ネットがつながらない環境でも仕事が可能です。そのため、NPUやGPUを搭載したラップトップPCのような端末上で動作するSLMを使うメリットとしては、事業継続計画(BCP)対策にも効果が期待できるというのもあります。
最近では、Microsoft社の「Copilot+PC」に代表されるように、PCにNPUやGPUを搭載した端末が登場しています。こうした端末を一台購入し、そこにSLMを導入して、社内で生成AIの活用法を試すといったことも可能です。活用方法が判明した後は、社員の全PCに展開していけば良いだけです。
オフラインでもSLMが効率的に実行できる(図版は日本AIコンサルティング社提供)
――LLMは中小企業では扱いづらいということでしょうか?
そんなことはありません。LLM自体は企業の大小に関わらず活用できますし、中小企業は大企業と比べて意思決定プロセスがシンプルな場合が多く、フットワークが軽いため、LLMの導入、活用をいち早く進めている場合がたくさんあります。
一方で、「社内のこの処理を自動化するために、クラウド型生成AIの機能を利用したい」といったニーズからLLMを使用するとなると、金銭的なハードルが高いかもしれません。なぜなら、そうした処理を行うためには、生成AIのAPIを利用する必要があり、多くのサービスではAPI利用のたびにコストが従量課金されるため、導入の仕方によっては、企業側に相当な金銭的な体力が要求されます。
とはいえ、LLMとSLM、どちらか一方を選ばなければいけないわけでもありません。高度な処理が求められない単純な作業であればSLMで十分ですし、センシティブなデータを扱うような、ローカル環境やエッジ端末上での処理が求められるケースにおいては、SLMやローカルで動作するLLMの利用が求められます。一方で、SLMで処理するにはどうしても難しい作業がある場合は、モデルの限界もあるため、一定のルールを守った上でクラウド版の最先端のLLMを使うべきです。
最終的には、適材適所で使い分けていくようになっていくと思います。SLMとLLMをハイブリッドで使うことは、これからの時代のスタンダードになると考えています。
実はSLM/LLMを区切る境界線は曖昧
――SLMには、どのようなモデルが存在するのでしょうか?代表的なモデルと選び方を教えてください
うーん、実はこのことを回答するのは簡単ではありません。なぜかというと、SLMの定義が、各社、各研究者によって異なるからです。
生成AIの学習モデルの大きさは「Billion(ビリオン)」という数値で表されることが多いのですが、たとえば3~4BillionぐらいまでをSLMとカウントする見方もあります。一方で、「いや、計算能力のレベルで見たら、10~15Billionぐらいまではまだ小規模じゃない?」「いやいや、24Billionまでは小規模でしょう」という見方もあります。そのため、ひとくちにSLMといっても、どのぐらいの規模のものを指すのか、簡単にはいえない側面があります。
当社では、ノートPCにおいて小規模なGPUでも動くレベルである4~5Billionくらいまでの規模のモデルをSLMとしています。
その前提でお話するのですが、たとえば中国・アリババの学習モデル「Qwen3」(クエンスリー)の小規模なモデルは0.6~4Billionなので、SLMといえるでしょう。このあたりのモデルでも、日本語を出力する能力は十分に備えています。また、Qwen3-30B-A3Bというモデルは30 Billion 級ですが、MoEを採用しているため、モデルの処理時に要求される計算規模は3~4Billionほどで、スムーズなテキスト生成計算処理を行うことが可能です。
さらに、同じぐらいの規模の学習モデルとしては、Googleの「GEMMA3」(ゲマスリー)というものがあります。こちらも1~4Blillionで日本語も出力可能で、4 Billion のモデルは画像の出力にも対応しています。
ChatGPTで知られるOpenAI社からは、「gpt-oss」というものがリリースされています。こちらの20 Billion というモデル(gpt-oss-20b)もMoEを採用しているため、モデルの処理時に要求される計算規模は3~4Billionほどで、スムーズなテキスト生成を行うことが可能です。
――これらのSLMを使い分けるポイントはどこにありますか
実際に使ってみて、自社にフィットするものを選択すべきでしょう。生成AIが出力するテキストは、必ずしも正しいものばかりではありません。ハルシネーションの問題もありますし、場合によってはコンプライアンスに違反するような、適切ではない振る舞いをする可能性もありえます。PoCで実際に使いながら検証するという作業は必要だと思います。
もちろん、誹謗中傷を含むテキストを生成する「毒性」や、特定の属性を差別するような「公平性の欠如」「ガバナンス」に関する評価や、RAGや回答精度を評価する手法はあります。このような手法で、最適なSLMを検討することも求められると思います。ただ最終的には「自社で納得して使うための実験」という工程は必要だと感じています。
オフラインの生成AI利用が加速すれば、
日々の業務の効率化も進む
――御社がすでにSLMを活用した事例があれば教えてください
当社が開発したSLMプラットフォーム「IB-Link」(アイビーリンク)が、まさにその具体例です。IB-LinkはCopilot + PC上で動作する生成AIで、リアルタイムの文字起こしや要約、RAG処理などのAI機能を、オフラインで実行することを可能にします。
IB-LinkはAIの環境構築やハードウェアの仕様にかかわらずAIアプリを簡単に作れる仕組みを提供します。アプリ開発者はこれをもとに業務支援アプリを構築し、中小企業の皆さまの業務改善を速やかに・効率的に行うことが可能になりました。
たとえば、デル・テクノロジーズ様とは「訪問医療向けのアプリ」を共同開発し医療機関様に提供しています。この手のアプリは通常、最低半年から一年くらいは開発にかかるのですが、おおよそ半分の期間で開発ができました。また、実際にご利用いただいた医療機関様からは「これまでメモを取っていた時間を、他の業務に充てられるようになりました。看護師の視点で患者の様子を観察したり薬の副作用を確認したりすることに集中できます」というコメントを頂いています。
――最後に、SLMが今後どのように進化していくのか、新居さんの見解を教えてください
現在はLLMモデルの生成AIの進化が目立ちますが、その裏側で同時に、SLMも進化していることを意味します。そうした進化により、3Blillion程度のSLMでも、翻訳、要約、情報収集といった業務においては、今以上に活用できるようになると予想しています。
SLMが利用できる端末もどんどん広がってきています。サーバーやワークステーション、ゲーミングPCに限らず、iPhoneやiPadのようなモバイル端末でも、小さいモデルであれば動かせる時代になってきています。必要最小限の能力を持ったSLMがスマホ・タブレット・ノートPC上に搭載され、オフラインで利用できるようになり、生成AIを使用することがより日常的になっていくと思われます。
もちろん、ビジネスのあらゆる場面をSLMだけでやり切るというのは、まだまだまだ難しいと思います。しかし、従業員全員が生成AIに対応した端末を持ち、全員がSLMを使いこなし、全員がSLMによって業務を効率化しながら働く未来は、そう遠くないうちに訪れると思います。
●インタビュイープロフィール

新居 桂陽(あらい・けいよう)
2023年、株式会社日本AIコンサルティングに入社。現在は同社でチーフデータサイエンティストを務めつつ、生成AIを活用した技術開発や、生成AIの業務ログ分析(AKT)への応用に取り組んでいる。研究・技術の両輪から、人とAIの共創を支える業務支援を目指している。





