
 テーマ / Theme
テーマ / Theme
ビジネスを加速させるための取り組みをご紹介
日本の製造業は、ものづくり大国と世界から評価された時代から環境が大きく変化しており、現在多くの課題を抱えている。
- 人口減少に伴い、労働力確保が困難
- 中堅中小企業の跡継ぎ不足や熟練工の退職により、次の世代への技術継承が困難
- 海外の人件費高騰やカントリーリスクによるサプライチェーンの頻繁な見直しによる管理の煩雑化
- 多様な消費者ニーズの変化による製品ライフサイクルの短縮化
- モノからコト消費(サービス消費)への変化に伴うビジネスモデルの見直し
- など
このような課題に対して、積極的に変化を受け入れ、先手を打って変革を成し遂げていくことが、競争力の強化に繋がり、新たなビジネスチャンスをつかむ原動力となる。

課題/ Issue
品質管理における課題

製造業では、安定的に一定の品質を担保した製品を作り続けていく必要がある。
品質管理部門は品質の維持・改善・保証のエキスパートとして、製品毎に基準を設け、品質を担保するために製品に対し検査を日々行っているが、現場では多くの課題が存在している。
例えば、ニーズの多様化により製品は複雑化するが、複雑化に応じて検査範囲も拡大する必要があるため、一定の品質を保つことは難しくなる。
このような状況の中で、これまでは熟練の技術者の目により品質を担保してきたが、熟練技術者の大量退職と後継者不足により、従来の方法による品質の担保が難し状況に陥ることが想定される。
実際の製造現場では、製造設備の劣化、気温・湿度などのさまざまな要因が不良品を発生させる原因となっている。このため、品質検査において不良品の割合などの生産状況をモニタリングし、基準値以上の不良品が検出された場合は、一度製造ラインを停止させ、原因を調査し、取り除くといった対応が必要となる。しかしながら、原因の特定と解消には時間を要することも多い。
こうした品質管理の問題に対し解決策を検討し、対策を講じていくことが、日本の多くの製造業に求められている。

概要/ Overview

このような製造業を取り巻く環境において、限られたリソースの中で品質を維持・管理し、さらに品質を高めていくためには、これまでの取り組みの延長線だけでは解決することが難しく、新たな品質に対する考え方や仕組みを取り入れていく必要がある。
その1つとして、“デジタル技術”と“品質に関するスキル・ノウハウ”の融合が挙げられる。限られた人員の中で、品質管理に関わる作業負荷軽減と品質維持の達成が見込めるだけでなく、AI(人工知能)に関連する技術を活用することで更に高度な品質管理の実現に期待が高まってる。
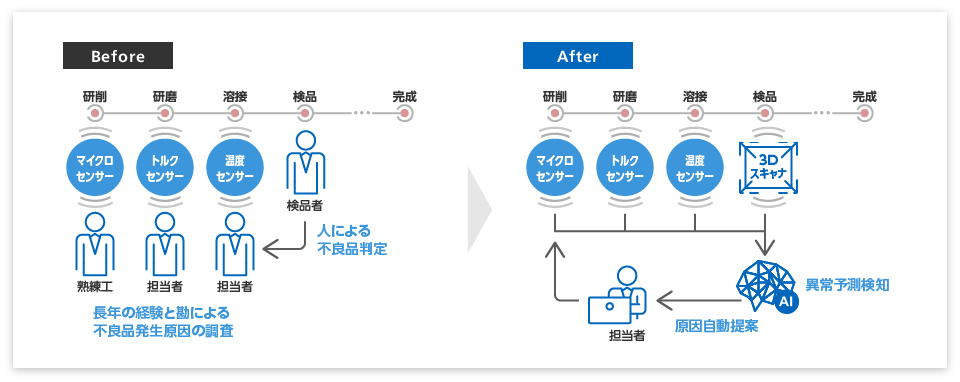
センサーやカメラから取得したデータの解析やAI(人工知能)の機械学習技術を活用することで、これまでの検品時(製品完成時の検査)ではなく、製造途中において、不良品発生を予測することが可能となる。さらに、不良品発生の原因特定とアクション候補の通知により、製造ラインの停止時間最小化と歩留まり向上を達成することが期待できる。
具体的には、製造設備には、関連する情報(温度、湿度、圧力、流量、加速度、変位、振動、電圧、電流など)を取得するためのさまざまなセンサーが取り付けられている。これらのセンサーから取得した値はデータロガーでロギングしたり、人手による目視確認と記録などを行うことで、時系列の数値データとして収集・蓄積することができる。
このようにして収集・蓄積したデータと品質検査結果をもとに構築した不良品発生の予測モデルを用いることで、製造途中における不良品発生の予測および不良品判定時の発生原因をタイムリーに特定することができる。
なお、予測モデルの作成は自動化することも可能となっている。予め保持している大量の機械学習アルゴリズムから最適な予測モデルを自動的に構築するソフトウェアも存在しており、このような技術を活用することで、高度な品質管理が実現可能となる。

 ユースケース / Use Case
ユースケース / Use Case
テーマを実現による業務の変化・メリットをご紹介
Use Case 1
不良品発生の予測・通知
各製造工程においては異常がないが、完成品の検品で不良と判定されるケースが存在する。不良品の発覚が遅れると、手直し工程が必要となり、生産性の悪化や、納期遅延の原因にもつながる。
このような問題に対し、各工程にセンサー・カメラを設置。これらから取得した情報を組み合わせ、AIで分析することで、完成品の検品前に不良品の発生を予測することが可能となる。
AIが、完成品の検品前に不良品の発生を予測し、各製造工程の品質管理担当者に通知。品質管理担当者は通知された情報にもとづき、製品を取り除くことができる。結果として、不良品となる仕掛品への製造コストを削減することができる。
効果
EFFECT- 不良品の早期発見による仕掛品への製造コスト削減
Use Case 2
不良品発生原因の予測と対応策候補の提示
不良品が発生した場合、さらなる発生抑止のため、製造ラインの全工程を停止し、原因の特定と対処を講じる必要がある。
これまでは、熟練技術者の経験にもとづく勘に大きく依存してきた。今後、熟練技術者の減少により、経験が少ない中堅・若手技術者が、不良品発生時の対応を行う機会が多くなると、試行錯誤を繰り返しながら対応することとなるため、原因の特定と対処に時間がかかる。
この問題を解決するために、熟練技術者は、経験や実績にもとづいた不良品の発生原因とそれに応じた対処法を、予めデータ化し蓄積する。不良品判定時に、AIが各種センターから取得したデータをもとに不良品の発生原因を予測し、予め用意した対処法の候補を提案する。
品質管理担当者は、不良品が発生した場合、製造ラインの全工程を停止した後、 AIから受けとった原因箇所と対処法の候補から、特定の工程・設備から調査し、対処を講じていくことで、製造ライン復旧までの時間を短縮できる。
効果
EFFECT- 不良品発生時における製造ライン停止時間の短縮
Use Case 3
予測モデルの自動作成と予測精度維持
ユースケース1のように、不良品発生などの現象を予見するためには、データサイエンティストの協力のもと、品質保証担当者が、予測モデルを構築する必要がある。予測モデルは、学習データ(=過去データ)にもとづき、統計手法などを活用し、最も精度の高いモデルを採用・構築する。しかし、構築した予測モデルの運用を開始すると、モデル構築時には十分考慮できていなかった条件(設備の摩耗等)について変化があった場合、予測モデルの精度は低下する。精度を維持させるためには、データサイエンティスと品質保証担当者が、定期的な条件の見直しとモデルの再構築を行わなければならず、非常に手間がかかる作業となる。
予測モデルをより手間をかけずに精度を維持する方法として、予め予測精度のモニターにより精度劣化を検知する仕組みと、精度劣化を検知した場合は、分析モデルの再構築とモデルの置き換えを自動化することで、精度を維持することができる。
データサイエンティストと品質保証担当者は、AI導入による効果が正しく期待する効果を得られているか確認するのみにとどまる。予測精度低下のモニターやモデル再構築・置き換えといった作業を軽減できる。
効果
EFFECT- 予測モデル作成・維持の工数削減
 リファレンスアーキテクチャ / Reference Architecture
リファレンスアーキテクチャ / Reference Architecture
テーマを実現するシステム構成をご紹介
主な前提・要件/ Assumptions & Requirements
- 製品は、一定の品質要件が存在し、基準を満たすように検査を実施し、出荷される。
- 組み上げや検査なども含めて生産リードタイムが長期間となる製品(例:エンジン)を製造しており、基本的に不良品を出してはならない(一品一品に品質が求められる)
- 製造ラインは複数拠点・複数工程に跨り分散している。
- 製品の品質に影響を及ぼす情報は複数存在しており、設備のセンサーによる数値測定やカメラによる画像撮影などで取得できる。(例:設備稼働状況や温度、など)
- 品質向上に向けて製造ラインのモニタリング・検知はリアルタイムが望ましい。
- 本製品の製造に関わるデータは、特質上、セキュリティが確保されたネットワーク環境(インターネットとは隔離された環境)に構築する。
アーキテクチャ上のポイント/ Point
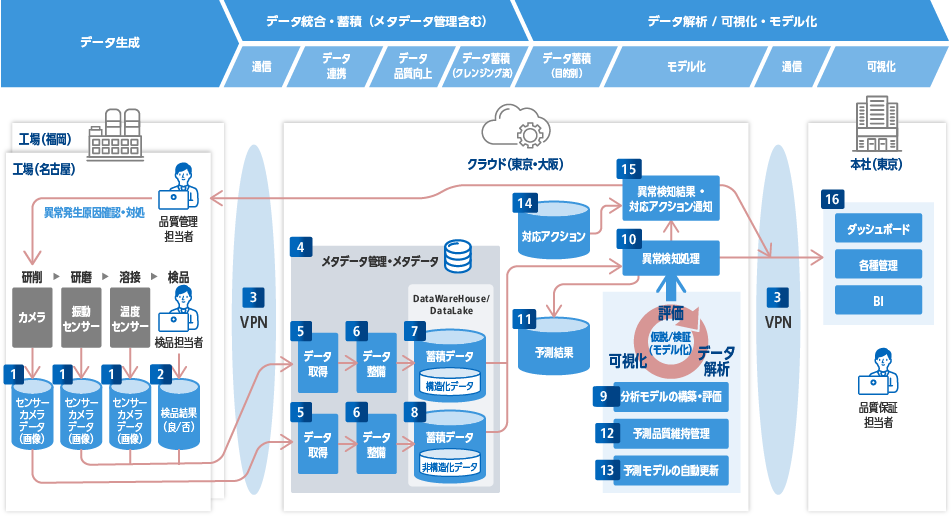
- 従来の人手による品質管理手法はあるものの、さまざまな課題が存在している。そのため、人工知能(AI)による統計的手法・機械学習を活用し、不良品発生の「予測モデル」を構築し、リアルタイムで不良品の発生を予測、検知、通知する仕組みを実現する。
- 工場ごとに製造工程や製品等の前提条件が異なるが、各工場を一元的に管理する。
- クラウド上で提供するデータの統合・蓄積・解析・モデル化を行う基盤を活用する。
- 「予測モデル」を自動的に評価・更新することで、予測精度(予測モデルの品質)を維持する。
- 工場・クラウド・本社を含め、ユーザーがアクセスする環境はすべてセキュアかつ一元的に運用する。
- 今回のテーマにおいて構築するアーキテクチャは、ユースケースに示す工場の生産ラインに特化した予測検知等のためだけではなく、本社のBIツール等へデータを連携し、見える化することで、意思決定等にも利活用できる仕組みを実現する。
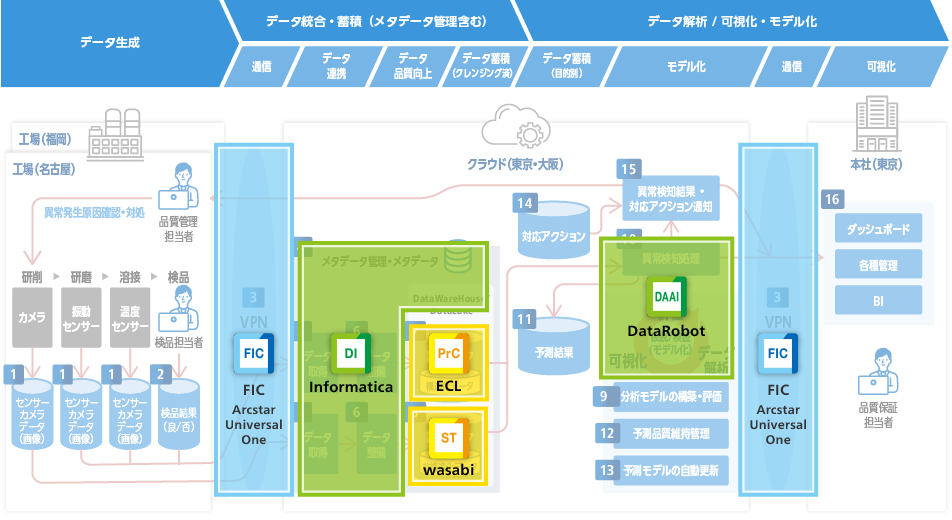
-
 Infomatica
Infomaticaデータインテグレーション さまざまなデータの統合を行うiPaaS機能をクラウドにて提供
-
 Enterprise Cloud
Enterprise Cloud信頼性と俊敏性を両立した企業向けクラウドサービス
-
 Wasabiオブジェクトストレージ
Wasabiオブジェクトストレージ大容量データを低コストに保管するオブジェクトストレージ
-
 DataRobot on Enterprise Cloud
DataRobot on Enterprise Cloudトップデータサイエンティストのノウハウを凝縮した機械学習プラットフォーム
-
 Flexible InterConnect
Flexible InterConnectマルチクラウド環境を簡単・柔軟に接続可能な次世代サービス

各機能説明
- 1センサ/カメラデータ
-
各工程の設備に設置されたセンサーやカメラ等から稼働データなどを取得します。
センサーより測定した数値データ(構造化データ)やカメラで取得した画像などのデータ(非構造化データ)は、独自形式を含むさまざまなフォーマットで記録されます。[ポイント]
- ・センサーの種類および数は、今後増加することが見込まれるため、それに耐えるアーキテクチャを実装する必要があります。
- ・将来実装されるセンサーの仕様は規定せず、データフォーマットやプロトコルなどは柔軟に対応できる仕組みが望ましいです(ただし、MVPアプローチであればよく、当初使用しない仕様を実装する必要はありません)。
- ・特殊な方式でない限り、製品を活用することで、開発を極小化すべき。
- ・非構造データを管理するためには、検索の内容を表すタグを付けることが必要です。
- ・センサーやカメラから集めるデータの収集頻度(秒、分、時間、日など)が可視化・分析する上での最も細かい単位になります。収集頻度に応じてデータ保存領域、クラウド等へデータを運ぶ回線速度、可視化・分析を行うためのリソース(CPU、メモリなど)が必要となり、最終的にはコストに跳ね返るため、目的を達成できる最適な収集頻度を決定する必要があります。
- ・各センサーからのデータ集約方式について決定が必要です(工場側で一時的に集約するか、ダイレクトにクラウド側に転送してしまうか、など)。選択した方式によっては、当リファレンスアーキテクチャでは触れていない仕組みを構築することが別途必要となります(工場側の一時集約のデータベースや、デバイス管理の仕組みなど)。
- 2検品結果
検品(製造工程を全て終え、完成した製品の品質を判定する工程)における品質確認結果を記録します。
- 3VPN
-
各工場(データ発生源)、クラウド(データ統合・蓄積・分析等の基盤)、本社(可視化・分析結果の判断等)といった拠点間通信について、セキュリティを確保し安全に接続します。
[ポイント]
- ・VPN(仮想プライベートネットワーク)の種類として、大きく「インターネットVPN」と「IP-VPN」の2つが挙げられます。取り扱う情報に応じて、VPNに求めるセキュリティ、品質(速度、遅延、利用可能時間など)、コストなどを考慮し、最適なVPNを選択する必要があります。
- ・IP-VPNは通信業者が独自に保有する閉域IP網を利用するVPNです。メリットは専用の通信経路を使うため、セキュリティレベルが高く安全な環境を構築することができます。サービス品質保証(SLA)がついていることも多く、複数拠点、大容量データのやり取りをするときでも通信が安定します。デメリットはコストが高いことです。
- ・インターネットVPNは、インターネットとIPSecやSSLといった通信の暗号化技術を組み合わせたVPNです。メリットはインターネットを活用することで低コストで導入できることです。デメリットとしては、トラフィックの混雑状況によって通信速度が遅く・大幅な遅延が生じるなど、品質が保証されないなどが挙げられます。
- ・通信が途切れると業務に大きな影響が生じることが想定される場合は、予め冗長構成を取ることが重要です。冗長構成の要素としては、アクセス回線(光回線と無線(LTE/3G))、お客様宅内の回線終端装置(ルータ、ONU等)や、データを置くクラウドの場所(東京、大阪)などが挙げられますが、構成要素毎にどこまで分散させるかを検討する必要があります。
- ・現在の業務だけでなく、今後の業務拡大(リモートワークや、O365やSalesForceなど各種SaaS事業者サービスの利用など)も考慮し、柔軟に対応できるVPNを選択することが望ましいです。
- 4メタデータ管理
-
メタデータとは、そのデータを表す属性や関連する情報を記述したデータのことを表します。メタデータの種類は以下の通りです。
- ・ビジネスメタデータ:テーブルやカラムの定義と説明、ビジネスルールなど
- ・テクニカルメタデータ:物理テーブルやカラムの名称、アクセス権など
- ・運用メタデータ:データ処理やアクセスの詳細など
非構造化データの場合、例えば、各工場でセンサーにより収集した数値データは、分析のためにデータの取得時間やどの設備で取得したデータなのかなどの情報が必要になります。以下のような項目が該当します。
- ・データ作成者
- ・データ作成装置
- ・作成日時
- ・収集場所
- ・データ整備、変更を加えたアプリケーション
- ・データ更新日時、など
これらの項目は、データ取得時やデータ整備時に付加されます。
メタデータ管理とは、メタデータを一元的にカタログ管理することです。データを大量に集めても、必要なデータがどこにあるか探し出せなければ利活用することは困難です。そこで予めメタデータを一元管理し、データ利用者が検索できる状態にしておきます。こうすることで、予測モデル構築に必要なデータを特定したいなど、データを利用したいと思った時に検索し、直ぐに必要なデータを特定することができます。
[ポイント]
- ・データ定義情報だけにとどまらないため、様々なメタデータソースが管理できる仕組みが必要です。
- ・企業内外のメタデータを統合して保持するために、データ統合ツールのアダプタ、スキャナ、ブリッジアプリーケションなどを使用して、自動的に収集することが望ましいです。
- ・システム間を移動するデータを把握するために、データ来歴管理が必要です。
- ・非構造データを管理するためには、検索の内容を表すタグを付けることが必要です。
- ・メタデータ管理自体、MVPアプローチで、目的や必要に応じて管理範囲や管理粒度を検討することが望ましいです。
- 5データ取得
-
「1.センサー/カメラデータ」および「2.検品結果」のデータを、クラウドに転送します。
本機能のデータの転送・取得間隔が、後続機能処理のボトルネックとなります。(例:リアルタイムによる不良品発生予測の可否)[ポイント]
- ・転送元と転送先として、さまざまなアプリケーションやクラウドがあり、接続方式もAPI、JDBC、FTPなどさまざまなものが考えられ、増減・変化することが予想されます。特殊な方式でない限り、製品を活用することで、開発を極小化することが望ましいです。
- 6データ整備
-
「5.データ取得」でクラウドに転送した生データ(ローデータ)は、データ処理・データ分析前にフォーマット変換、データの補正・修正、データセットの統合などを行い、データ形式の標準化、属性データの付与、異常値の除去などを実施する必要があります。これらのデータ精度を高める一連の作業は、一般的にはデータプレパレーションと呼ばれています。
データプレパレーションは、整備ルールを決定するところに非常に多くの時間がかかりますが、精度の高い分析をするためには避けて通れない、重要なプロセスです。代表的なデータ整備の例を以下に列挙します。代表的なデータ整備の例を以下に列挙する。
- ・フォーマット変換
-
- -数字の型・桁合わせ
- -時刻情報の統一(JSTからUTC変換)
- -半角・全角を全角に揃える、など
- ・属性データの付与
-
- -シリアルやロットなど最終的に完成する製品個体との紐づけ
- -取得した装置・製造工程、など
[ポイント]
- ・メタデータ管理と合わせて、データ標準化が重要です。
- ・同様に、MVPアプローチで随時、追加・変更・削除ができる方式を採用することが望ましいです。
- ・データ取得と合わせて、特殊な方式でない限り、製品を活用することで、開発を極小化することが望ましいです。
- 7蓄積データ(構造化データ)
-
「6.データ整備」において整備した各データを蓄積するためのデータプールです。主に、リレーショナルデータモデルとして管理されているデータを対象とします。リレーショナルデータベースにより実装されます。
[ポイント]
- ・これらの仕組みは、全社的に標準的・汎用的な仕組みとして実装することが望ましいです。
- ・もし、なんらかの事情により、全社的(あるいは共通的)な仕組みを実装できない場合でも、今後実装する同様の検知機能や対象となるデータ種類・数の増加を想定して、全社的な仕組みに昇華できるようなアーキテクチャと必要な機能のみ実装することが望ましいです。
- ・管理するデータのサイズに応じて、適切なサービス(コストを重視したフリーのDBMS、信頼性や大規模データの運用も可能な商用DBMSの選択)やストレージ(ハードディスク、フラッシュストレージ)等を採用する必要があります。
- 8蓄積データ(非構造化データ)
-
「6.データ整備」において整備した各データを蓄積したデータプールです。主にリレーショナルデータモデルとして管理されていないデータを対象とします。主にデータレイクにより実装されます。
[ポイント]
- ・これらの仕組みは、全社的に標準的・汎用的な仕組みとして実装することが望ましいです。
- ・なんらかの事情により、全社的(あるいは共通的)な仕組みを実装できない場合でも、今後実装する同様の検知機能や対象となるデータ種類・数の増加を想定して、全社的な仕組みに昇華できるようなアーキテクチャと必要な機能のみ実装することが望ましいです。
- 9予測モデルの構築・評価
-
各種センサ等から収集した数値データや画像データなどの情報をもとに、統計手法や機械学習手法を駆使し、最も高い精度で不良品発生を予測するモデルを構築します。
[ポイント]
- ・AIにおける予測モデルの構築は、計算機科学について深い知識や経験を持つデータサイエンティストの手によって行われています。一方で、AIの適用領域の拡大やビジネス上の価値について急速に認知度が高まっていることもあり、データサイエンティストを求める企業が増え、人材が不足している状況となっています。このような状況を打開するため、近年ではデータサイエンティストに成り代わり、ソフトウェアによる予測モデル構築の自動化が実現されてきています。世界の優れたデータサイエンティストの知識や経験、ベストプラクティスを予め実装しており、精度の高い予測モデルの自動構築を実現しており、積極的な活用をご検討いただきたいです。
- 10異常検知処理
-
蓄積データを「9.予測モデルの構築・評価」で構築した予測モデルで判定し、不良品の発生を予測します。予測結果は、「11.予測結果」に蓄積します。
[ポイント]
- ・当リファレンスアーキテクチャでは、クラウド側にて異常検知処理を行うため、工場側にサーバ等は不要としていますが、お客様要件によっては工場側にサーバ等を設置し異常検知処理を行うことなどを検討する必要があります。
- 11予測結果
「10:異常検知処理」において判定された予測結果を蓄積しているデータベースです。
- 12予測品質維持管理
-
保持している「11:予測結果」に基づき、予測モデルの精度劣化を検知します。
[ポイント]
- ・ビジネスシーンでは予測モデルの作成時点から短期間で周辺環境が変化することも多く、当初構築した予測モデルを使い続けると、予測精度の低下(予測モデルの陳腐化)が発生するため是正する対応が必要となります。
- ・予測モデルの精度劣化を検知するためには、予め品質の維持管理プロセスを整備しておくとともに、当初想定していた予測精度との乖離を確認し、是正していくことが必要です。
- 13予測モデルの自動更新
-
AIによる予測モデルの精度劣化を検知した場合、予測精度を維持するために予測モデルの更新が必要となります。この予測モデルの更新を自動的し、高い頻度で行うことで、予測精度の維持・向上を実現します。
[ポイント]
- ・れまで予測モデルの構築・更新はデータサイエンティストの手によって行われてきました。一方でビジネス領域におけるAI活用が拡大していく中でデータサイエンティスト不足が課題となっています。このようなデータサイエンティスト不足に対し、製品を活用することで改善を図ることが可能です。
- 14対応アクション
熟練技術者の経験や実績にもとづいて、不良品の発生原因とそれに応じた対処法をあらかじめデータとして蓄積したデータベースです。
- 15対応アクション通知
「10:異常検知処理」において、異常(不良品発生の予測)が検知された場合、対応すべきアクションを「14:対応アクション」より取り出し、リアルタイムで担当者に通知します。
- 16ダッシュボード・各種管理・BI
-
BIとは「Business Intelligence」の略です。蓄積された大量のデータを分析して、分析結果を経営の意思決定に活用するための仕組みであり、データを利活用していくためこのBIをシステム化したものが「BIツール」です。
現場のデータをタイムリーに分析して、ビジネス施策を実施したり、改善策・対策を講じたり、経営に生かしたいという考えのある企業に向いております。まず現状を見える化するためにモニタリング、その結果を踏まえて、今後の対応を検討、新たな分析軸や指標でトライ&エラーを実施することができます。
BIツールには主に以下の機能が存在します。- ・ダッシュボードによるレポーティング機能
- -グラフィカルなレポート描画機能等によりデータを可視化します。
- ・OLAP分析機能(多次元分析機能)
- -複数のデータの関係性を複数の角度から仮説検証・確認することができます。ある問題点についてその結果に至った要因がどこにあるかを調査するなど、データウェアハウスなどに蓄積された大量データを利活用して多次元データベース(キューブ)により複雑な分析を素早く行うことができます。
複数の軸を含む多次元データモデルを取り扱うことで、データの集計レベルを1つずつ掘り下げて集計項目をさらに詳細にするドリルダウン(多次元的にディメンションの高い階層から低い階層へと集計値を参照していく分析方法)などにより詳細化したりすることができます。 - ・データマイニング機能
- -データの中からルールや法則性を導出、仮説ではなくデータそのものの間での法則・関連性を分析します。
- ・シミュレーション機能
- -データによる予測により意思決定のための判断や提言を行います。
このページのトップへ