

最新ICT環境をオブザーバビリティで最適監視
近年利用が拡大しつつある複雑かつ動的でクラウドネイティブなシステムは、従来の運用監視ツールといった手法では状態の把握が困難になりつつあります。このような課題を解決する「オブザーバビリティ(可観測性能)」を活用したエンジニアリング、モニタリング手法について解説します。

DX推進のためにクラウドネイティブへの移行が進む
IDC Japan株式会社は、2022年の国内クラウド市場は売上ベースで前年比37.8%増、2022~2027年の国内クラウド市場規模の年間平均成長率を17.9%と推計しました。これにより、2027年の市場規模は2022年の約2.3倍に達する見込みと予測します。その要因としては、従来型ITからクラウドへの移行が進んでいることなどが考えられます。一方、企業のDXへの投資は拡大しつつあり、今後はDXが国内クラウド市場を牽引していくという予測もあります。このような状況を受けて、今後はクラウド利用が前提となる、クラウドネイティブ型システムが主流になっていくことは想像に難くありません。
国内クラウド市場 用途別売上額予測、2022年~2027年
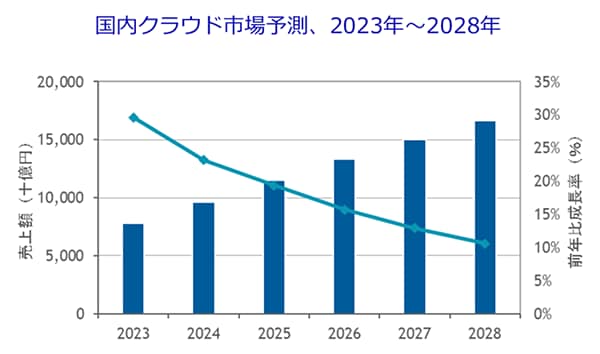
出典:IDC Japan株式会社「国内クラウド市場 用途別売上額予測、2022年~2027年」
https://www.idc.com/getdoc.jsp?containerId=prJPJ50993923
クラウドネイティブ型システムを定義すると、クラウドでのアプリケーション実行やソフトウェア開発などを前提としたシステムとなります。複数のマイクロサービスを組み合わせて1つのアプリケーションを構築することで、複雑かつ動的で伸縮自在のエラスティック(elastic)な分散システムの構成になっています。アプリケーションを機能などの細かい単位で切り分ける構造から、マイクロサービスアーキテクチャとも言われています。似たような言葉で、アプリケーションの実行に必要なクラウドリソースを動的に割り当てるサーバーレスアーキテクチャがあり、用途に応じて使い分けるのが一般的です。
マイクロサービス化したアプリケーションは、コンテナサービス上で稼働します。コンテナとはOS上に論理的な領域を作成することで、アプリケーションの動作に必要なライブラリなどを統合し、OSなどのリソースを論理的に分けることにより、複数のコンテナでリソースを共有して使えるようになります。1つのOS上で複数のアプリケーションが動作する、PCやスマートフォンなどをイメージするとわかりやすいかもしれません。ちなみに、コンテナをシステム的に実行させるソフトウェアをコンテナオーケストレーションと言います。代表的なところでは、Googleが社内で利用していたコンテナ管理ツールを汎用化した、Kubernetesなどが知られています。
クラウドネイティブ型システムに話を戻します。すべて同一のモジュールで作り上げる従来のモノリシック型のシステム構成に比べ、クラウドネイティブ型の分散したシステム構成は機能の追加や変更、スケーラビリティや可用性の確保が容易になるなど、とくにシステムの開発と運用の業務において大きなアドバンテージが生じます。つまり、データドリブンな経営や事業運営、スピーディなDXの推進といった次世代のビジネス展開には、従来型IT(モノリシック型システム)からクラウドネイティブ型システムへの移行が必須と理解してよいでしょう。
なぜ、オブザーバビリティが注目を集めているのか
従来の監視手法であるモニタリングでは、事前に監視対象として設定したログやCPU、メモリーなどのリソース、メトリクスを収集し、エラーを検知します。しかし、複雑で動的にスケールするクラウドネイティブ型システムでは、従来のモニタリングでは通用しなくなりつつあります。なぜなら、インシデントが発生した場合に原因の特定が困難になるといった問題が起こるためです。
従来のモノリシック型のシステム構成では、アプリケーションのスローダウンや異常停止などが発生した際、構成が明確であり変化することも少ないため、原因の特定は容易でした。しかし、クラウドネイティブな分散システムはサービスが稼働するインフラが多岐に分散し、インシデントが発生した際には全マイクロサービスの動きを追従する必要があります。加えて、各アプリケーションが動的に変化することもあるため、従来のモニタリングでは原因を突き止めるのはきわめて難しくなってくるのです。
こうした問題を解決するために、昨今注目を集めているのが「オブザーバビリティ(Observability)」です。Observe(観察する)とAbility(能力)を組み合わせた造語であり、日本語に翻訳すると「可観測性」や「観察する能力」となります。Oとyの間にある11文字のアルファベットを略して、「O11y」「o11y」と表記されることもあります。オブザーバビリティという言葉自体の歴史は長く、1960年にルドルフ・カルマンが線形力学系の分野で初めて「システム内部の状態を外部出力の情報から推測できる度合いを示す指標」として使用しました。その用語が、近年同じ意味合いでICT分野でも使われるようになってきました。
オブザーバビリティ(observability)は、従来のモニタリングを包含するエンジニアリングの概念です。従来のモニタリングは、ログに吐き出されるエラーメッセージの監視に加え、ログでは判別できない詳細なエラーをAPM(アプリケーションパフォーマンス監視)で監視するなど、「何が起きているのかを見続けること」のみでした。しかし、オブザーバビリティは利用者のUX(User experience:ユーザー体験)を意識して、未知の領域も含めたサービス全体を可視化することで、「予期せぬことが起きたときに、なぜそれが起きたのかを突き止める、UXを損ねる事態が生じる前に対処すること」を目指しています。
従来のモニタリングとの違いは、エンドツーエンドでのフルスタック監視の実現により、未知のインシデント対応、アラート対応が可能になることです。その概要をたとえるなら、ビルなどに設置された異常を検知する「監視カメラ」がモニタリングで、ビル内を巡回して異常の予兆に気づき、原因を突き止め、未然に異常を防ぐ「ガードマン」がオブザーバビリティのようなものでしょうか。
オブザーバビリティを実現するには、データの収集、データの分析、データの可視化という3つのアクションが必要です。そこで、オブザーバビリティではCPU使用率などのリソース状況、レイテンシなどのサービス状況といった定量的な指標となる数値である「メトリクス」、アプリケーション処理で発生するリクエスト構造や各コンポーネントの処理時間である「トレース」、OSやミドルウェア、アプリケーションなどが出力する個別イベントである「ログ」というテレメトリーデータを活用します。
それぞれについて、もう少し説明を加えていきます。「メトリクス」とは、定期的に取得したシステムCPU使用率やメモリー使用量、ネットワークトラフィックなどをグループごとにまとめたデータのことです。メトリクス自体は単なる数値のため、時系列に並べてグラフなどで可視化します。メトリクスは、システムのパフォーマンス測定に適した指標であり、時系列のグラフは従来のモニタリングでも広く利用されてきました。
「トレース」とは、マイクロサービスを構成する複数サービスをアプリケーション処理で発生するリクエスト構造や、各コンポーネントの処理時間などで横断的に監視する機能です。トレースによりマイクロサービス間を横断していくリクエストの追跡や問題箇所の特定、デバッグが容易になります。
「ログ」とは、OSやミドルウェア、アプリケーションが出力するイベントの履歴です。一般的にログは、イベントの内容や付随データをタイムスタンプと一緒にプレーンなテキストの形式で出力します。いつ、何が、システムのどこで起きたのかを把握するためには欠かせないデータがログです。
つまり、メトリクスで「何が起きているか」を秒単位で検知し、トレースで「どこで問題が起きているか」を判別し、ログで「なぜ問題が発生したのか」を究明します。各データを相関づけて連携することで単なるデータ収集ではなく、「どこまで容易に状況を捉えて、事象を正確に把握できるか」「どこまで容易に観測できるか」を担保することがオブザーバビリティの重要なポイントです。そのほかにも、どのようにアプリケーションが実行され、どこでどの程度のリソースが割り当てられたことを示すデータである「プロファイラ」、システムのクラッシュ時に出力されるメモリーデータの「ダンプファイル」を利用する方法もありますが、一般的にメトリクス、トレース、ログがオブザーバビリティの3本柱と呼ばれます。
オブザーバビリティの実現により、ソフトウェアエンジニアやDevOps、SRE(サイト信頼性エンジニアリング)などの担当者がテレメトリーデータを活用できるようになります。なお、SLO(サービスレベル目標:Service Level Objective)などを指標にすることで、よりデバッグが正確かつ容易になります。これにより、いくつかのメリットが得られます。まず、システムのリアルタイムな状態把握や切り分けにより問題への迅速な初動対応が実現され、システムの可用性の向上が図られ、ダウンタイムの短縮やMTTR(平均修復時間)が改善できることです。加えて、アプリケーションのセキュリティも強化できます。そして、ユーザーに対するサービスレベルの維持を容易にすることで、UXも向上できるでしょう。
最近のトレンドとして、オブザーバビリティのプラットフォームにICT運用を目的とした人工知能である「AIOps」を実装するケースも増えています。AIOpsの目的は人に代わってAIが膨大なテレメトリーデータから、どんな問題が起きているか、どこで起きているか、なぜ発生したのかを究明することです。AIOpsの実装により分析などが自動化でき、さらなるオーバーヘッドの削減が実現できます。
体感品質を軸にオブザーバビリティをスタートする
オブザーバビリティを実現する統合監視ツール/製品は、各ベンダーから提供されています。一般的な統合監視ツールは、システムのデータをリアルタイムで収集する機能やデータを分析する機能、分析結果を可視化する機能を持ち、複雑で動的にスケールする環境でも、いつ、何が、どこで起きているのかを把握できるようになります。しかし、これらの統合監視ツールを運用に落とし込むのは容易なことではありません。なぜならインシデントの状況を把握できても、それが影響を及ぼす範囲や適切な回復策の見極めが難しく、その結果、属人的なナレッジやドキュメント頼りになってしまうためです。現在、日本では慢性的なデジタル人材不足が深刻化し、さらに複雑化、高度化するICTにアジャストできる質の高いプロフェッショナルも希少化しているため、なおさら運用のハードルは高くなります。
オブザーバビリティ実現の第一歩として、まずは体感品質、つまり社内ユーザーのUXをきちんと可視化してみてはいかがでしょうか。たとえば、NTTコミュニケーションズの「お客さま体感品質モニタリング・スマート」は、ネットワークのエンドツーエンドの体感品質をモニタリングデータとしてリアルタイムにダッシュボードで可視化することにより、ネットワークに潜む課題を把握し、解決、可用性の向上を実現するサービスです。
通信の種類やエンドユーザー別にエンドツーエンドのネットワーク品質を可視化することで、ネットワーク全体を把握した品質のモニタリングが可能です。さらに品質の問題が確認された場合、ボトルネック調査により速やかな原因特定も実現します。リモート環境からのヘルスチェックに有効なスピードテストも可能で、その結果、課題が特定のユーザーにみられる場合、ユーザーごとのWi-Fi強度やPCパフォーマンスを確認することで原因の特定につなげることもできます。見えざるボトルネックを抜本的に解決できれば、社内ユーザーのUX向上に寄与することに加え、問い合わせやクレーム対応が軽減されることにより、運用担当者のストレスや稼働が抑えられるメリットも期待できます。
しかも、高度な技術や高価な複数ライセンスの購入が不要で1端末から廉価に導入できるのもメリットと言えるでしょう。業務拡大によるモニタリング範囲の増減、スモールスタートでの部分導入など、利用環境に合わせた無駄のないスケーラビリティな料金設計ができるようになっています。加えて既存のPingやSNMP Trapといったアクティブ・モニタリングでは把握困難だったボトルネックや帯域幅の逼迫も可視化でき、データにもとづいた的確なユーザー体感の品質モニタリングを実現します。利用回線や接続機器など監視対象の制限がないため、環境の把握が困難なICT環境のモニタリングにも最適です。このようなことから、オブザーバビリティ実装の布石となることが期待できます。
お申し込みも簡単で、サイトにアクセスして必要事項を入力し、PCなどのデバイスにソフトウェアをインストールするだけで簡単にモニタリングが開始できます。手軽に導入できるため、お試しで使ってみて、効果を測定してから本格導入を検討してみてもいいでしょう。情報システム部門が実質的に1人体制あるいは少人数体制の組織であった場合などは、その有用性がさらに実感できることでしょう。オブザーバビリティのポイントは、UXを意識し、UXを損なう前の迅速な対処にあります。特定しづらい社内ユーザーの体感品質を可視化し、UXを向上するために導入する価値は大いにあるのではないでしょうか。